
Both Parent files and Children are processed through a series of static analysis modules used to exact information from the file. The full analysis results for each file can be displayed by clicking the title bar in the file window on the Results page.

The collapsed view of the window only the displays high level information about the file including the SHA256 hash, the file name if available, YARA labels, and file characteristics such as the type of file (EXE, DLL), the size of the file, and the compile time.
File Hashes
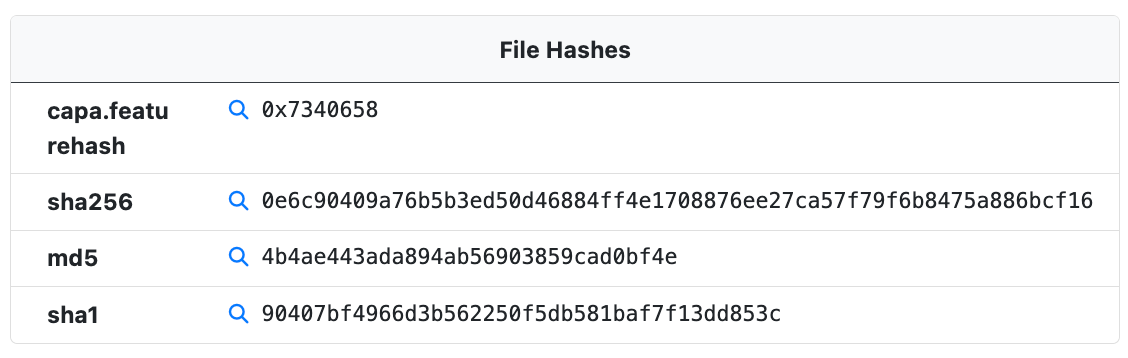
The File Hashes module provides hashes that can be used to identify the sample. In addition to an MD5, SH1, and SHA256 hash of the sample itself the following hashes may also be included.
- inflated – When an artificially inflated submission is defaulted a SHA256 hash of the original submission is linked to the defaulted sample. This hash can be used to identify the original sample.
- ZIP – When a sample is submitted in a ZIP file a SHA256 hash of the ZIP file is linked to the sample.
FeatureHash
The capa.featurehash is a hash of the extracted CAPA features which can be used to hunt for samples with similar features.
Icon Dhash
When an icon is present in the PE resources the larges icon with the largest colour depth is extracted and a unique hash is generated call a dhash. Dhash stands for "difference hash" which is a special hash used for comparing images. Icon dhashes are also searchable and can be a useful pivot for identifying related samples.
Icon Fuzzy Dhash
In addition to a standard dhash, a fuzzy dhash is also generated for extracted icons. While dhashes typically serve to identify find similar images, we've noticed an increase in icons which use transparency and other techniques aimed at altering the dhash of visually identical images.
Metadata
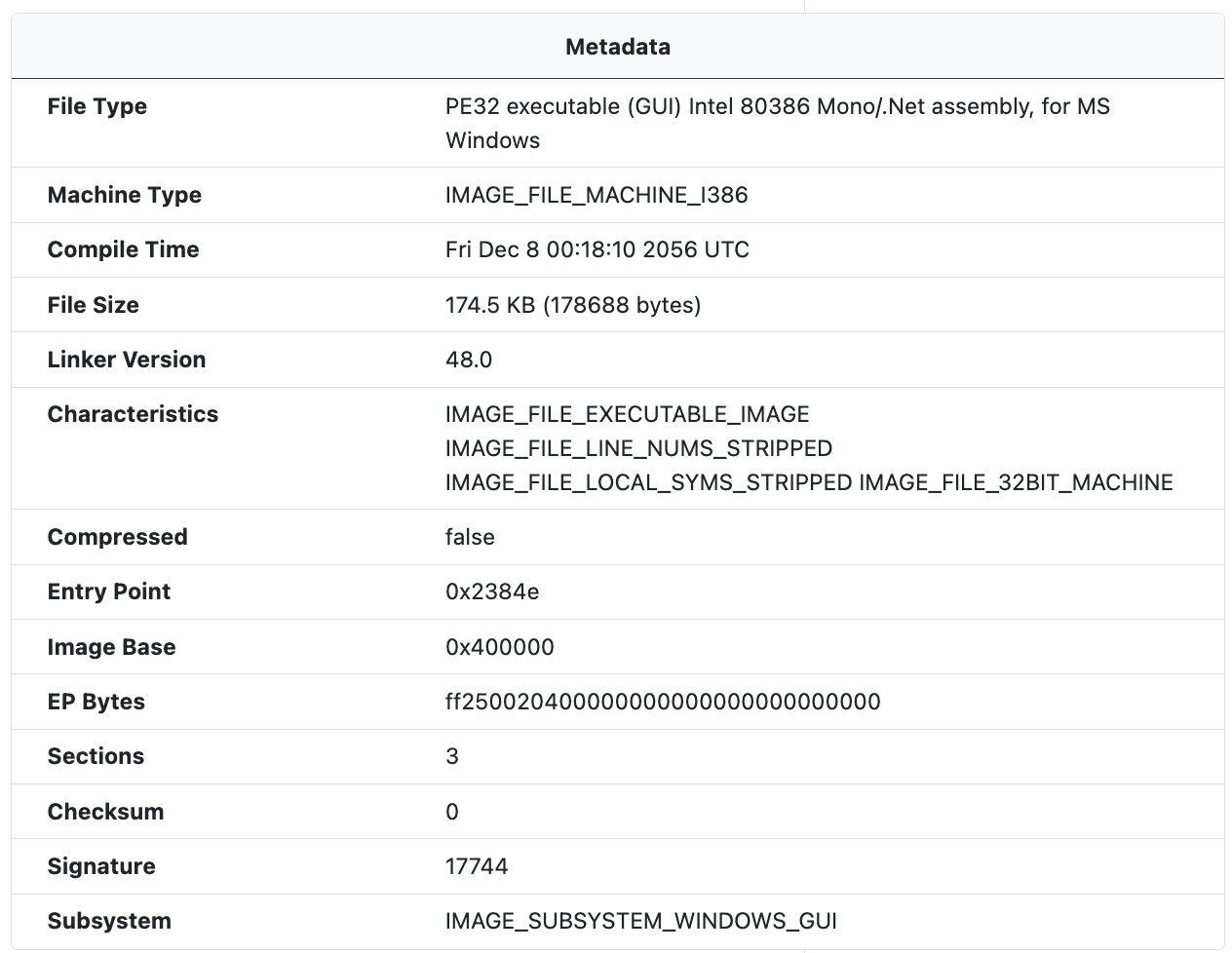
The Metadata module extracts PE metadata from the sample including the PE type, the machine type, and characteristics, among other information.
Goodware
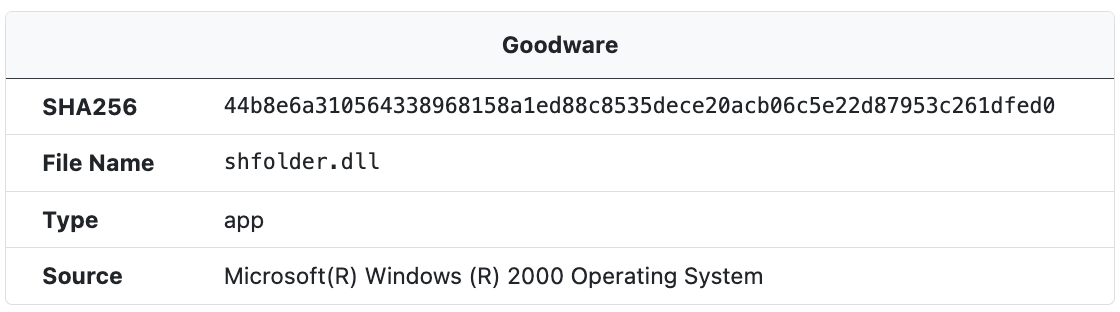
When a sample SHA256 hash matches with a hash in the UnpacMe Goodware repository a Goodware label and information about the file's origin is presented in the Goodware window.
Rich Headers
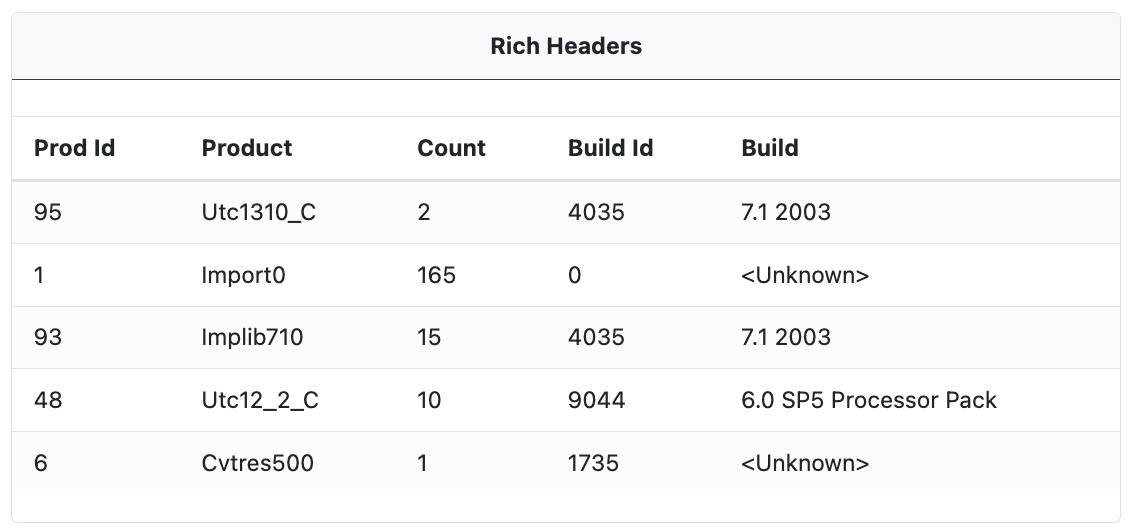
When available, embedded Rich Headers are extracted from the sample. These contain information about the compiler and build process (linker version, import library, resources, etc). The Rich Headers can list multiple compiler versions as a single executable can be built from multiple object files, and those object files can be compiled with different versions of a compiler.
Though officially undocumented the following Rich Header information is often extracted.
Prod Id: This is the product identifier. It's used to identify the tool or compiler that was used to build part of the executable.Product: This is a human-readable interpretation of the product identifier. It represents the tool or compiler that was used. For example, "Utc1310_C" refers to Microsoft C (MSVC) compiler version 13.10.Count: This is the number of objects that were linked from the corresponding product.Build Id: This is an identifier for the build of the tool or compiler. It's not always clear how this corresponds to the actual version of the tool or compiler.Build: This is a human-readable interpretation of the build identifier. It represents the version of the tool or compiler that was used. For example, the "7.1 2003" build identifier refers to the version of the Microsoft Visual Studio software used to compile the code. In this case, "7.1" is the version number of Visual Studio, and "2003" is the year of release. So, "7.1 2003" refers to Microsoft Visual Studio .NET 2003.
File Version Information
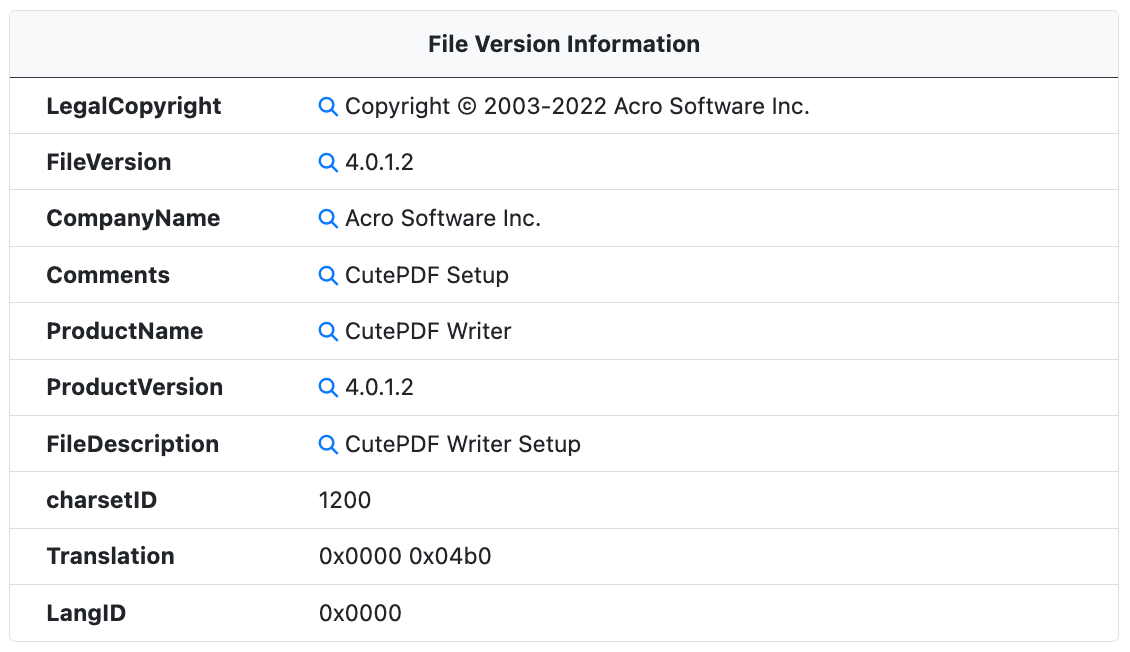
When available, the File Version Information metadata is extracted from the PE resources. This metadata is used to identify the software, version, and developer.
Resources

When available, information from the PE Resources table is extracted and displayed as an expandable tree. Each resource entry has a type, size, and an offset in the PE file.
Detect It Easy
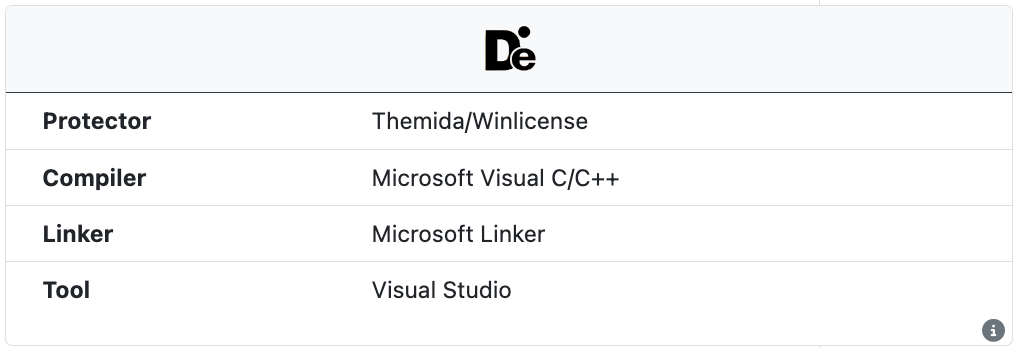
The open source tool Detect It Easy (DIE) is run on all samples to extract information about the compile and linker. DIE also identifies some common installers, protectors, packers, and obfuscators. This information is independent from the internal UnpacMe packer detection engine.
GoReSym
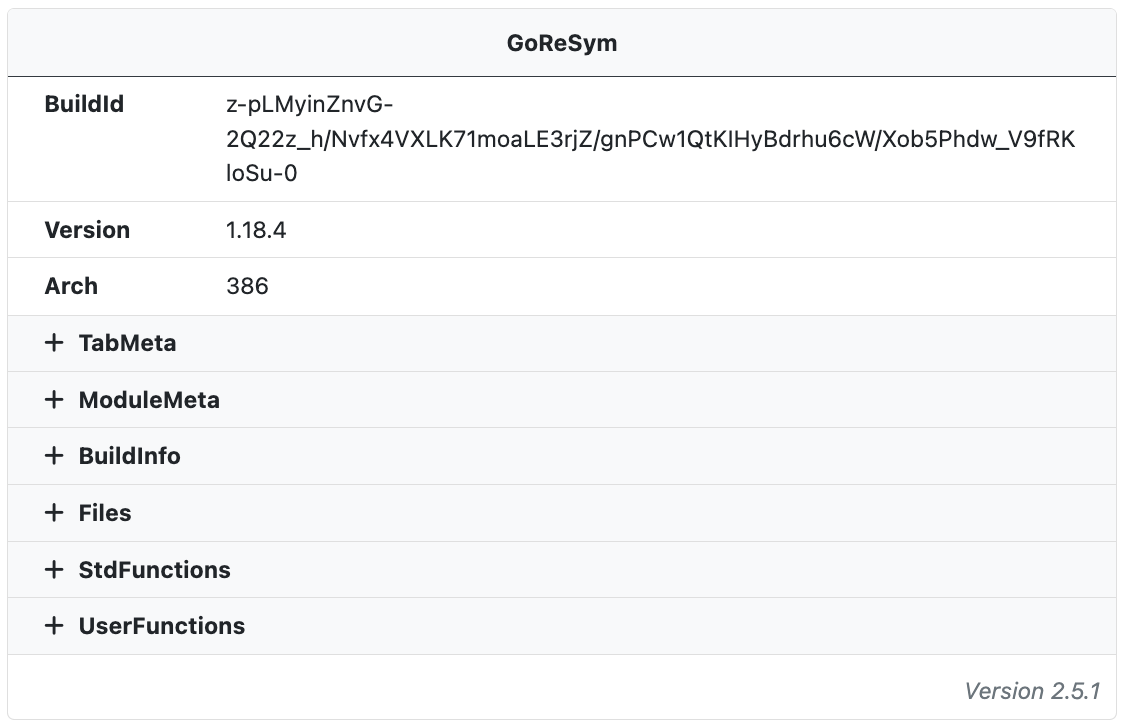
The open source tool GoReSym is run on all Go binaries and used to extract information about the Go build environment. The symbol parser extracts program metadata (such as CPU architecture, OS, endianness, compiler version, etc), function metadata (start & end addresses, names, sources), filename and line number metadata, and embedded structures and types.
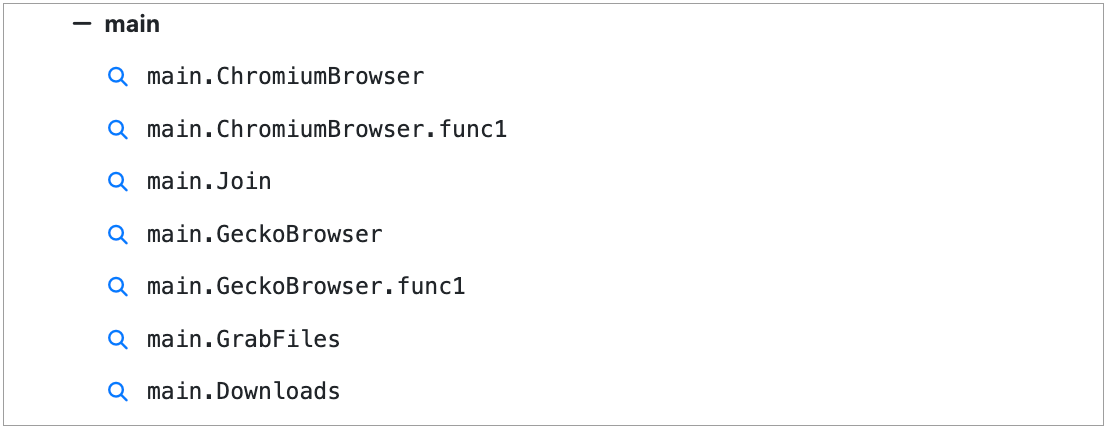
Of particular interest are the method names in the UserFunctions section, specifically the main module. Often these method names directly indicate the functionality of the binary and can be used to hunt for similar samples.
.NET Analysis
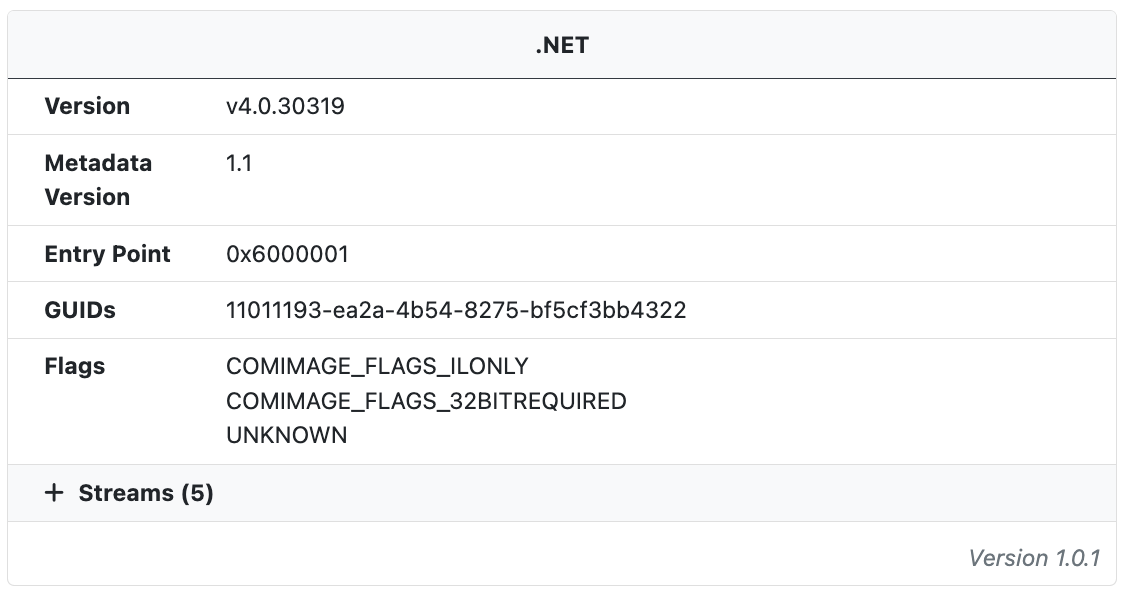
When .NET binaries are detected additional information about the .NET runtime and assembly is extracted. In addition to build metadata the streams are also extracted and labeled with their name, offset, chi2 value, entropy, and MD5 hash.
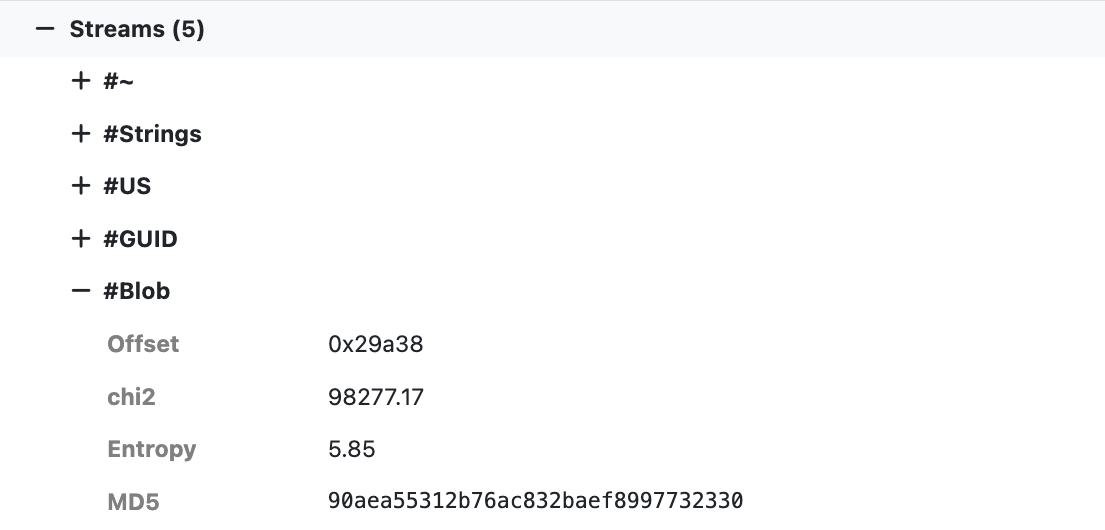
All useful pivots for hunting related samples!
CAPA

The open source tool CAPA is run on all samples. CAPA is a signatures based tool that statically extracts capabilities. For example, detection of anti-VM strings in a binary might indicate that the binary has VM evasion capabilities. The extracted capabilities are categorized and displayed in an expandable tree. All capable are searchable enabling analysts to hunt for samples with shared capabilities.
CAPA is resource intensive and may not complete processing on all samples prior to the end of the analysis process. In these cases CAPA results may not be displayed though the analysis has completed.
AV Detections

AntiVirus detections are displayed for antivirus matches on the file. Each detection lists the antivirus engine and the detection label applied by the antivirus.
YARA Labels

YARA labels are displayed for matches from the internal UnpacMe rule set as well as the Malpedia rule set. These labels are searchable.
UnpacMe rules include links to OSINT information related to the sample identified by the rule, while Malpedia rules include a link to the Malpedia entry for the rule.
Community Rules
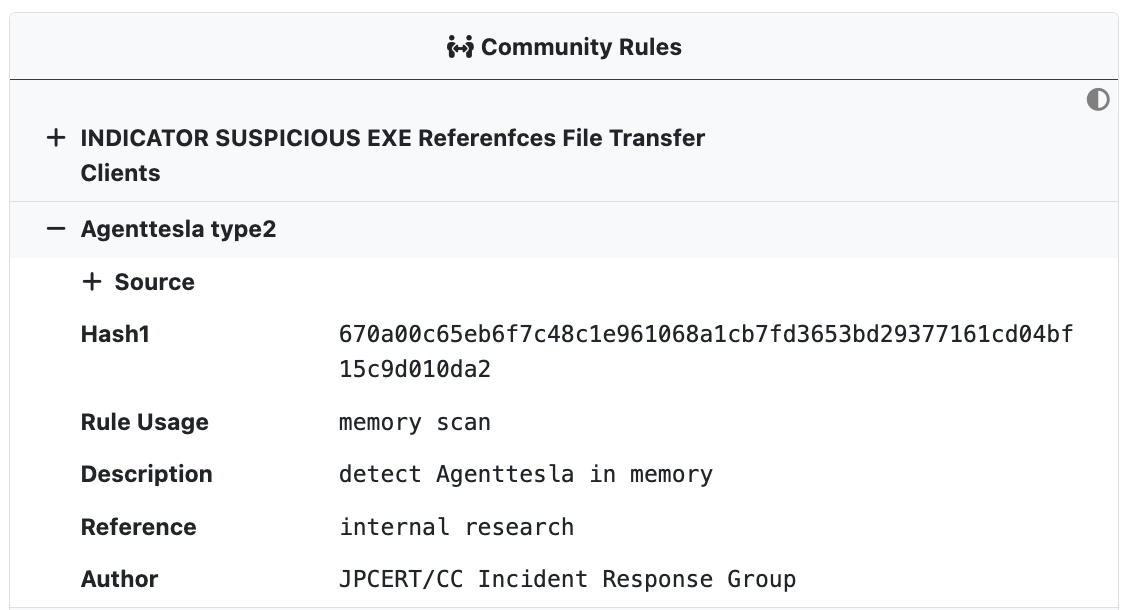
UnpacMe maintains a curated collection of open source community Yara rules which are run against all samples. Rule hits are displayed in the Community Rules window and are searchable.
Each rule match can be expanded to display rule details including the author, the source repository, and any metadata associated with the rule.
Imports Table
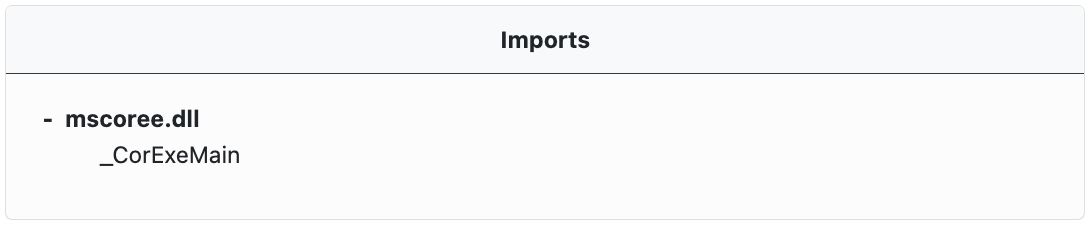
Where available, PE imports are extracted and displayed in an expandable tree in the Imports window. Imports refer to external functions that the executable file needs to call or use. These are typically functions from a Dynamic-Link Library (DLL) file. The PE file's import table lists all the DLLs and their respective functions that the executable file will import and use when it runs.
Exports Table
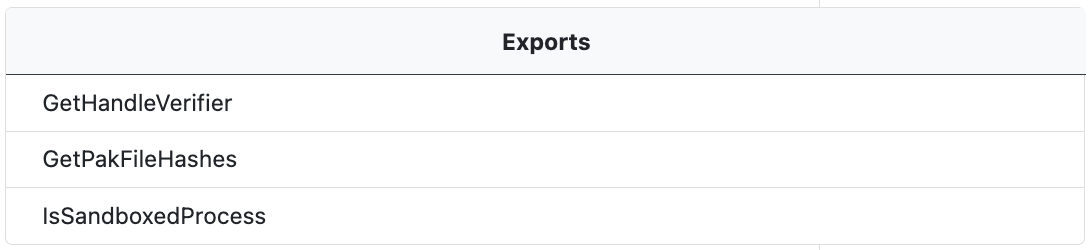
Where available, PE exports are extracted and displayed in an expandable tree in the Exports window. Exports refer to functions that the file makes available to other programs. These are typically functions that are intended to be used by other executables or Dynamic-Link Library (DLL) files. The PE file's export table lists all the functions that it exports.
Sections Table
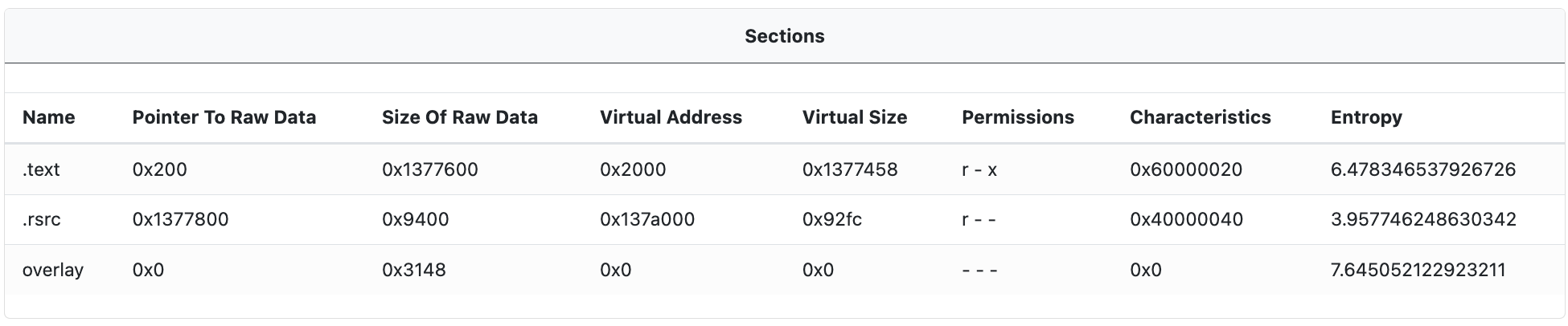
The PE section table entries are parsed and displayed in the Section Table window. The section table provides information about the different sections of the PE file. Each entry in the section table corresponds to a section of the PE file, such as the .text section (which contains the executable code), the .data section (which contains initialized data), or the .rsrc section (which contains resources).
Each section entry contains the following information about the section.
Name: This is the name of the section. Common names include.text,.data, and.rsrc.Pointer To Raw Data: This is the offset in the file where the section's data begins.Size Of Raw Data: This is the size of the section's data in the file.Virtual Address: This is the address where the section will be loaded into memory when the PE file is executed.Virtual Size: This is the size of the section when it is loaded into memory.Permissions: This indicates the access permissions for the section, such as whether it can be read, written, or executed.Characteristics: This provides additional information about the section, such as whether it contains code or data, and whether it is initialized.Entropy: This is a measure of the randomness of the data in the section. It can be used as an indicator of whether the section contains compressed or encrypted data. High entropy suggests the data is compressed or encrypted, while low entropy suggests it is not.
Strings
Ascii and Wide strings are extracted from each sample in displayed in the Strings window. Each strings table is displayed in a separate tab.
Copy Strings
The full strings list in the current tab can be copied to the clipboard using the copy-to-clipboard button (1).